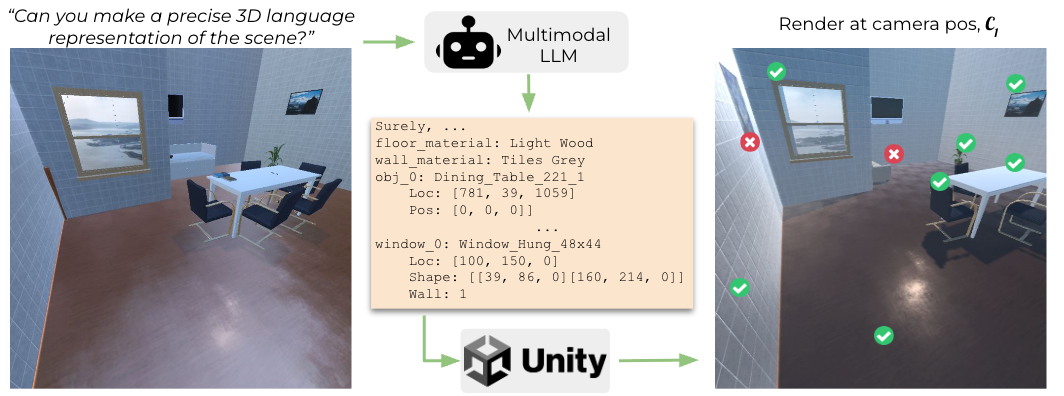
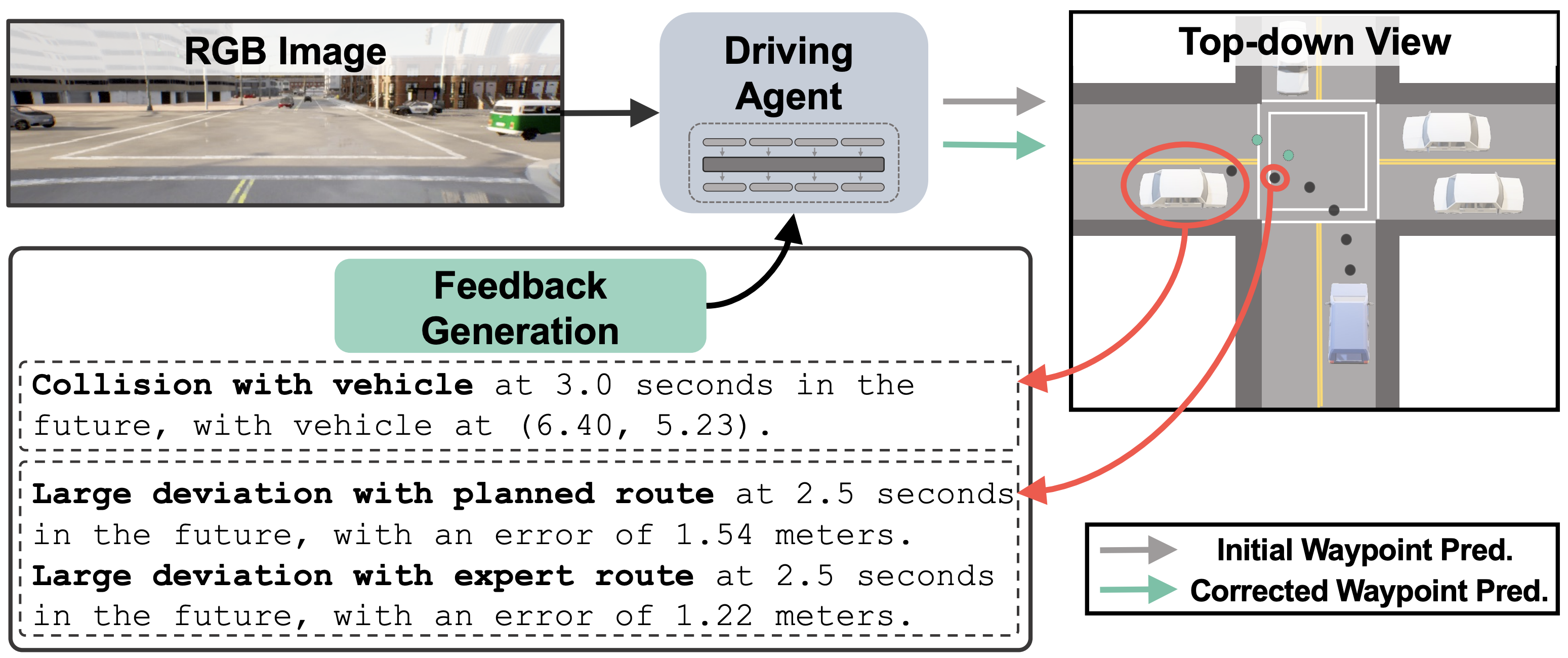
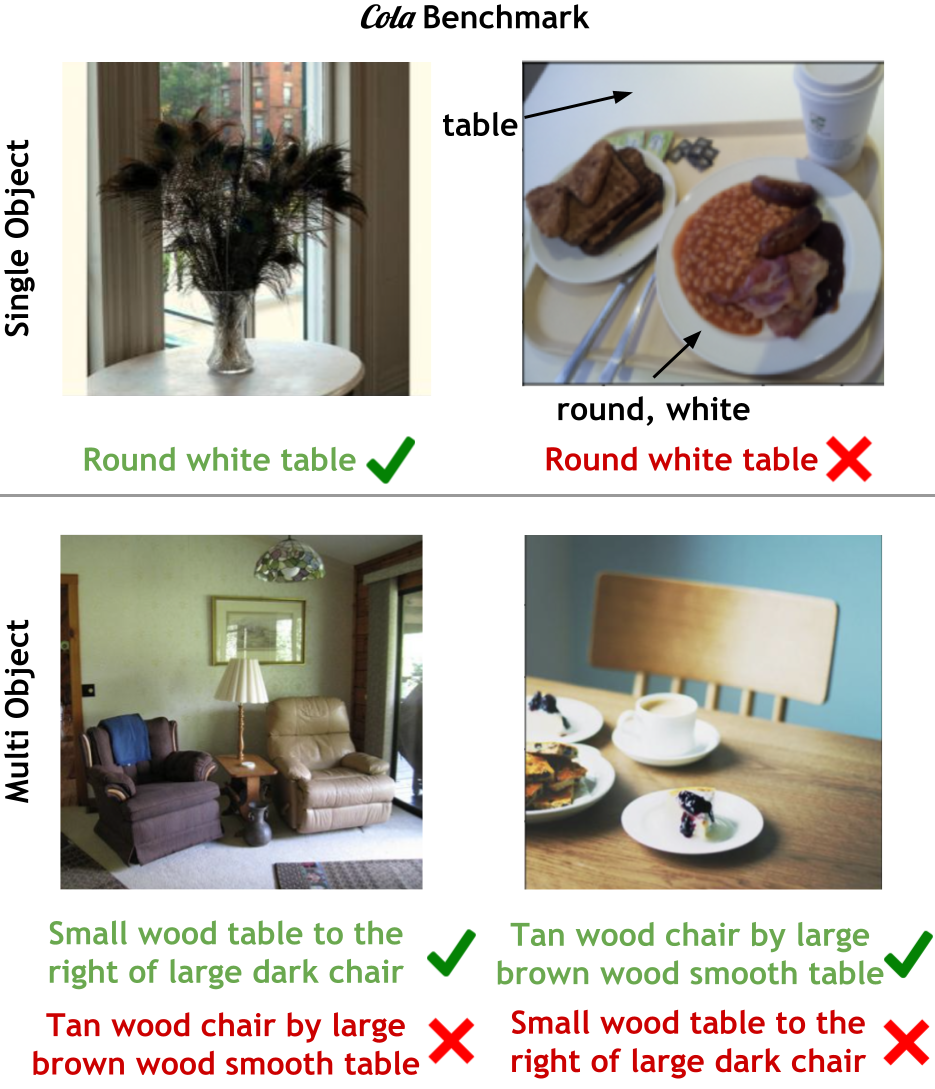
I wish to teach machines to help humans achieve more.
About me:
I am a Computer Vision Ph.D. Student, advised by Kate Saenko and Bryan Plummer at Boston University, and by Ranjay Krishna at the University of Washington. I received my M.S from Virginia Tech, advised by Devi Parikh.
I am interested in advancing visual and textual reasoning in AI models. To address the difficulty in obtaining detailed reasoning annotations, my work uses simulations to teach causal interactions and reinforcement learning to discover reasoning processes that generalize to the real-world.
If you are interested to collaborate or just chat about research on multimodal models and world models, say hi!